
正则表达式必知必会学习笔记。
1. 正则表达式入门
正则表达式的两种基本用途:搜索和替换。
2. 匹配单个字符
匹配纯文本
1 | hello //这里的正则表达式直接使用纯本文 |
匹配任意字符
1 | # .字符可以匹配到任何一个单个字符 |
匹配特殊字符
1 | # .字符在正则表达式里有着特殊的含义。如果模式里需要一个.,需要在.前面加上一个\字符来怼它进行转义 |
3. 匹配一组字符
匹配多个字符中的某一个
1 | # [abc] |
利用字符集合区间
1 | # 以下两者等价 |
字符区间还包括以下这些:
- A-Z,匹配从A到Z的所有大写字母
- a-z,匹配从a到z的所有小写字母
- A-F,匹配从A到F的所有大写字母
- A-z,匹配从ASCII字符A到ASCII字符z的所有字母。这个模式一般不常用。
注:-(连字符)是一个特殊的额元字符,作为元字符它只能用在[和]之间。在字符集合以外的地方,-只是一个普通字符,只能与-本身相匹配。因此在正则表达式里面,-字符不需要被转义。
1 | # 在同一个字符集合里可以给出多个字符区间。 |
取非匹配
除了那个字符集合里的字符,其他字符都可以匹配。
1 | [ns]a[^0-9]\.xls |
注:^的效果将作用于给定字符串集合里的所有字符或字符区间,而不是仅限于紧跟在^字符后面的那一个字符或字符区间。
4. 使用元字符
对特殊字符进行转义
1 | # 匹配一个包含着[和]字符的JavaScript数组 |
匹配空白字符
| 元字符 | 说明 |
|---|---|
| [\b] | 回退(并删除)一个字符(Backspace键) |
| [\f] | 换页符 |
| \n | 换行符 |
| \r | 回车符 |
| \t | 制表符(Tab键) |
| \v | 垂直制表符 |
匹配特定的字符类别
匹配数字(与非数字)
| 元字符 | 说明 |
|---|---|
| \d | 任何一个数字字符(等价于[0-9]) |
| \D | 任何一个非数字字符(等价于[^0-9]) |
匹配字母和数字(与非字母和数字)
| 元字符 | 说明 |
|---|---|
| \w | 任何一个字母数字字符(大小写均可)或下划线字符(等价于[a-zA-Z0-9]) |
| \W | 任何一个非字母数字或非下划线字符(等价于[^a-zA-Z0-9_]) |
匹配空白字符(与非空白字符)
| 元字符 | 说明 |
|---|---|
| \s | 任何一个空白字符(等价于[\f\n\r\t\v]) |
| \S | 任何一个非空白字符(等价于[^\f\n\r\t\v]) |
5. 重复匹配
有多少个匹配
匹配一个或多个字符:要想匹配同一个字符(或字符集合)的多次重复,只要简单地给这个字符(或字符集合)加上一个+字符作为后缀就行了。+匹配一个或多个字符(至少一个;不匹配零个字符的情况)。
在给一个字符集合加上+后缀的时候,必须把+放在这个字符集合的外面。比如[0-9]+。
1 | # 匹配邮箱 |
+是一个元字符。如果需要匹配+本身,就必须使用它的转义序列\+
注:一般来说,当在字符集合里使用的时候,像.和+这样的u按字符将被解释为普通字符,不需要转义,但转义了也没有坏处。[\w.]的使用效果与[\w\.]是一样的。
匹配零个或多个字符:*的用法和+完全相同。
1 | # 匹配邮箱(邮箱第一个字符必须是一个字母或数字字符) |
匹配零个或一个字符:?只能匹配一个字符(或字符集合)。
1 | http:\/\/[\w./]+ |
匹配的重复次数
重复次数用{ }字符来给出,把数值写在它们之间。
{ }是元字符。如果需要匹配{ }本身,就应该用\对它们进行转义(有时候不转义也能正确处理)。
1 | # 继续上面RGB那个例子 |
为重复匹配次数设定一个区间:{2,4},表示最少重复2次、最多重复4次。
1 | # 检查日期的格式 |
匹配至少重复多少次:{3,}表示至少重复三次。
防止过度匹配
常用的贪婪型元字符和它们的懒惰型版本:懒惰型元字符的写法很简单,只需要给贪婪型元字符加上一个?后缀即可。
| 贪婪型元字符 | 懒惰型元字符 |
|---|---|
| * | *? |
| + | +? |
| {n,} | {n,}? |
1 | # 文本为:living in <B>AK</B> and <B>HI</B> |
6. 位置匹配
边界
1 | # 文本为:The cat scattered his food all over the room. |
需要解决的问题:模式把文本中所有cat都找了出来,但是scattered里的那个cat我们不需要。
解决办法:使用边界
单词边界
第一种边界(也是最常用的边界)是由限定符\b指定的单词边界。顾名思义,\b用来匹配一个单词的开始或结尾。
\b匹配的是一个这样的位置,这个位置位于一个能够用来构成单词的字符(字母、数字和下划线,也就是与\w相匹配的字符)和一个不能用来构成单词的字符(也就是与\W相匹配的字符)之间。
1 | # 上一个例子 |
如果不像匹配一个单词边界,请使用\B。
1 | # 文本为:Please enterthe nine-digit id as it appears on your color - coded pass-key. |
字符串边界
用来定义字符串边界的元字符有两个:要给是用来定义字符串开头的^,另一个是用来定义字符串结尾的$。
如果^实在一个字符集合的外面并位于一个模式的开头,^将匹配字符串的开头。
1 | # ^匹配一个字符串的额开头位置,所有^\s*将匹配一个字符串的开头位置和随后的零个或多个空白字符(这解决了<?xml>标签前允许有空格、制表符、换行符等空白字符的问题)。 |
分行匹配模式
有许多正则表达式都支持使用一些特殊的元字符去改变另外一些元字符行为的做法,用来启用分行匹配模式的(?m)记号就是一个能够改变其他元字符行为的元字符序列。在分行匹配模式下,^不仅匹配正常的字符串开头,还将匹配行分隔符(换行符)后面的开始位置(这个位置是不可见的):类似的,$不仅匹配正常的字符串结尾,还将匹配行分隔符(换行符)后面的结束位置。
1 | # 使用正则表达式把一段Java代码里的注释内容全部查出来 //注释 |
注:有许多正则表达式实现不支持(?m)。
7. 使用子表达式
子表达式
子表达式是一个更大的表达式的一部分;把一个表达式划分为一系列子表达式的目的是为了把那些子表达式当作一个独立元素来使用。子表达式必须用( ) 括起来。
( )是元字符。如果需要匹配( )本身,就必须使用它的转义序列\(和\)
1 | # 不正确写法,将会重复匹配多个; |
以下语句是为了把文本中的年份数字完整的匹配出来,这个模式里的|字符是正则表达式里的或操作符,19|20将匹配数字序列19或20。
1 | 19|20\d{2} |
子表达式的嵌套
例子: 优化前面IP匹配的模式
解决思路:
- 以0开头的只能有一位;
- 以1开头后面有0-2位数字;
- 以2-9开头后面有0-1位数字;
- 任何一个以2开头、第2位数字在0-4之间的三位数;
- 任何一个以25开头、第3位数字在0-5之间的3位数字。
1 | ((2(5[0-5]|[0-4]\d))|(1\d{0,2})|0|[2,3,4,5,6,7,8,9](\d){0,1})(\.((2(5[0-5]|[0-4]\d))|(1\d{0,2})|0|[2,3,4,5,6,7,8,9](\d){0,1})){3} |

8. 回溯引用:前后一致匹配
回溯引用匹配
需要解决的问题:假设有一段文本,你想把这段文本里所有连续重复出现的单词找出来。
1 | # 文本为:This is a block of of text, several words here are are repeated, and and they should not be. |
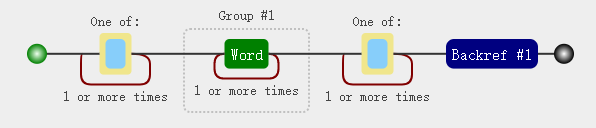
这个模式的最后一部分是\1:这是一个回溯引用,而它引用的正是前面划分出来的那个子表达式:当(\w+)匹配到单词of的时候,\1也匹配单词of;当(\w+)匹配到单词and的时候,\1也匹配单词and。
例子:
1 | # 文本: |

这里我们把[1-6]用括号括起来了,使它成为一个子表达式。然后就可以在结束标签</[hH]\1>中用\1来引用这个子表达式了。
回溯引用在替换操作中的应用
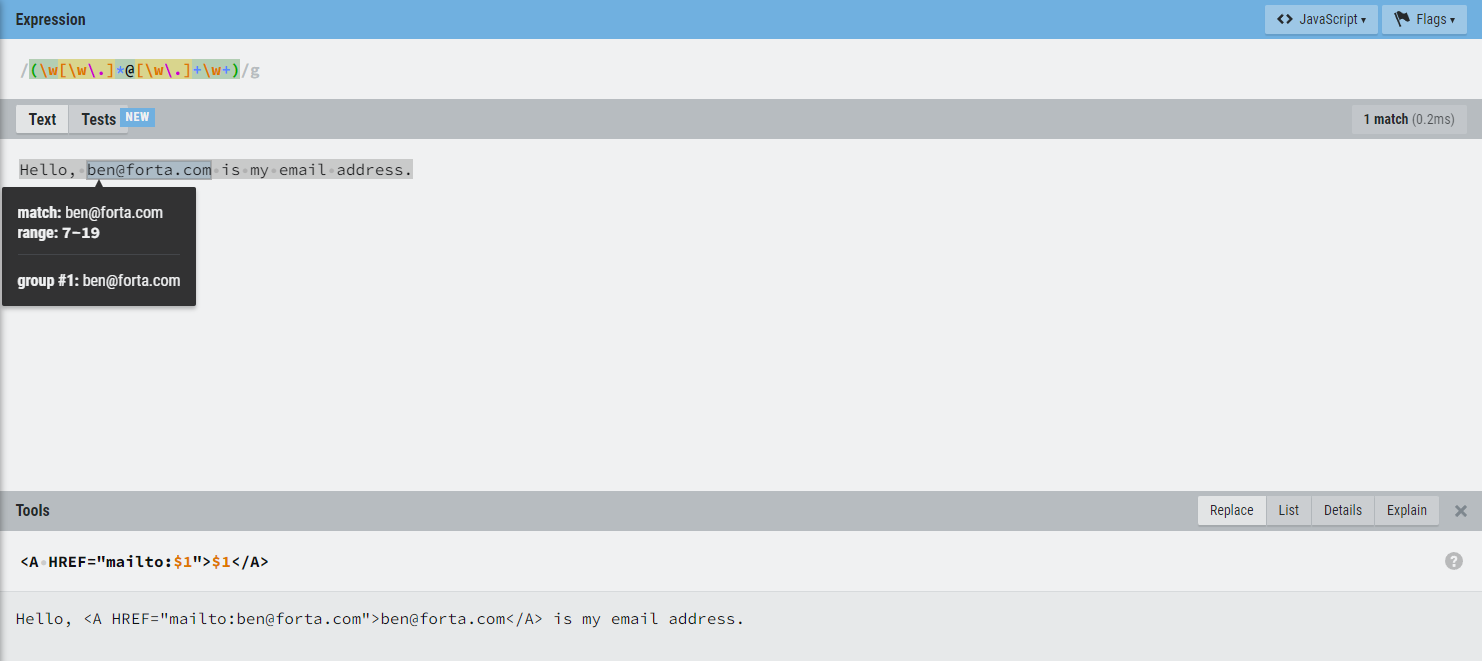
例1:将原始文本里的电子邮件地址全都转换为可点击的链接。
1 | # 文本 |
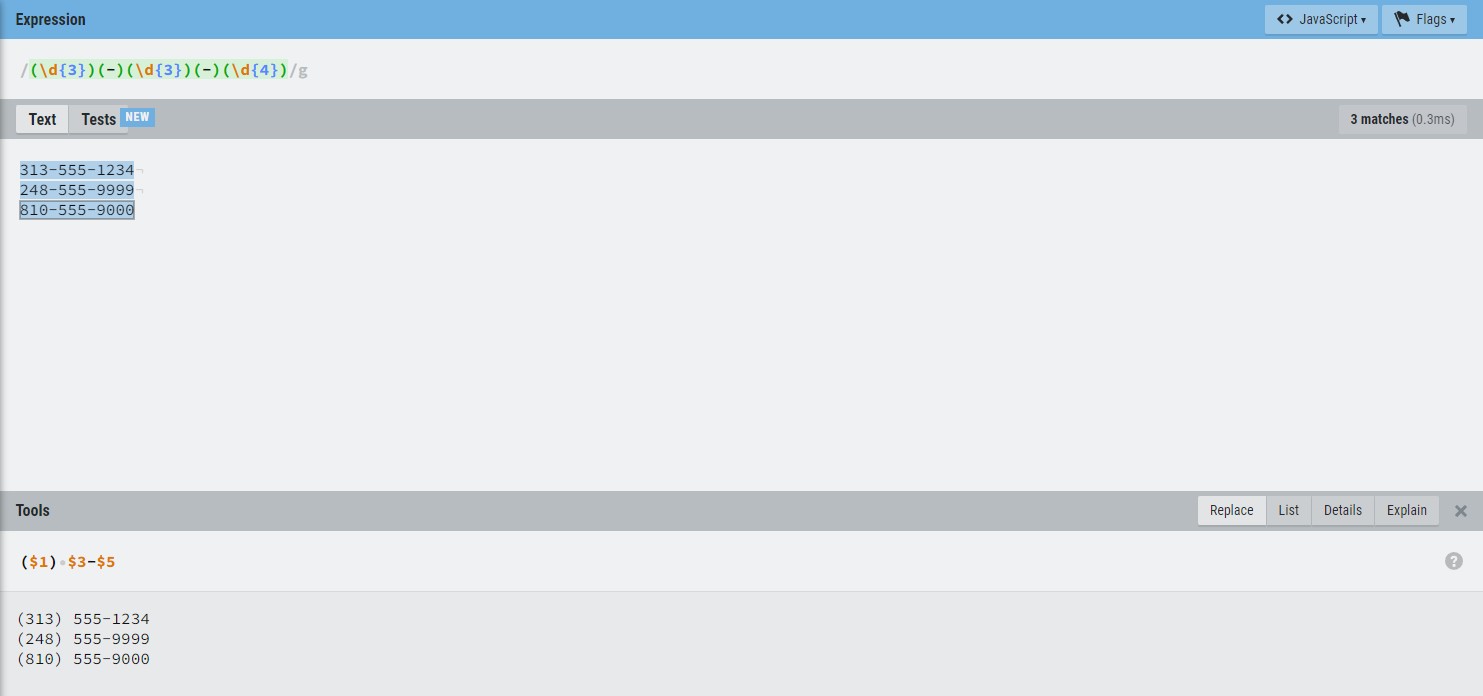
例2:电话号码格式转换。
1 | # 文本 |
大小写转换
用来进行大小写转换的元字符
| 元字符 | 说明 |
|---|---|
| \E | 结束\L或\U转换 |
| \l | 把下一个字符转换为小写 |
| \L | 把\L到\E之间的字符全部转换为小写 |
| \u | 把下一个字符转换为大写 |
| \U | 把\U到\E之间的字符全部转换为大写 |
\l和\u只能把下一个字符(或子表达式)转换为小写或大写。\L和\U将把它后面的所有字符转换为小写或大写,直到遇到\E为止。
例子:把一级标题(
…
)的标题文字转换为大写。1 | # 文本 |
注:该例子在调试工具中报错,不知道问题出在那里。
9. 前后查找
目前为止,我们见过的正则表达式都是用来匹配文本的,但有时我们还需要用正则表达式标记要匹配文本的位置(而不仅仅是文本本身)。这里就需要用到前后查找的概念
向前查找
向前查找指定了要给必须匹配但不在结果中返回的模式。从语法上看,一个向前查找模式其实就是一个以?=开头的子表达式,需要匹配的文本跟在=的后面。
例子:将文本中的url地址的协议名部分提取出来(为下一步处理做准备)
1 | # 文本 |

向后查找
向后查找操作符是?<=,?<=与?=的具体使用方法大同小异;它必须用在一个子表达式里,而且后面跟要匹配的文本。
例子:从产品目录中把产品价格提取出来。
1 | # 文本 |
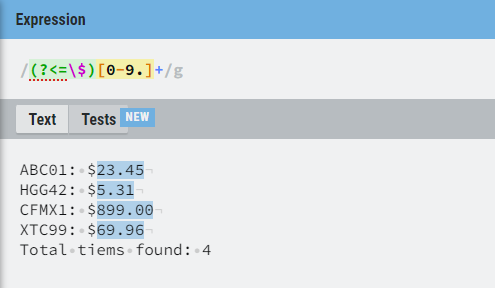
把向前查找和向后查找就结合起来
例子:把一个WEB页面的页面标题提取出来(title标签内的内容)。
1 | # 文本 |
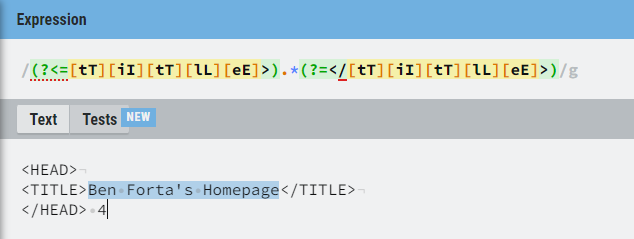
前后查找取非
各种前后查找操作符
| 操作符 | 说明 |
|---|---|
| (?=) | 正向前查找 |
| (?!) | 负向前查找 |
| (?<=) | 正向后查找 |
| (?<!) | 负向后查找 |
10. 嵌入条件
嵌入条件的两种情形:
- 根据一个回溯引用来进行条件处理。
- 根据一个前后查找来进行条件处理。
回溯引用条件
例子:把一段文本里的标签全都找出来;不仅如此,如果某个
标签是一个链接(被括在A标签之间)的话,你还要把整个链接标签匹配出来。
语法:(?(backreference)true-regex)
1 | # 文本 |

